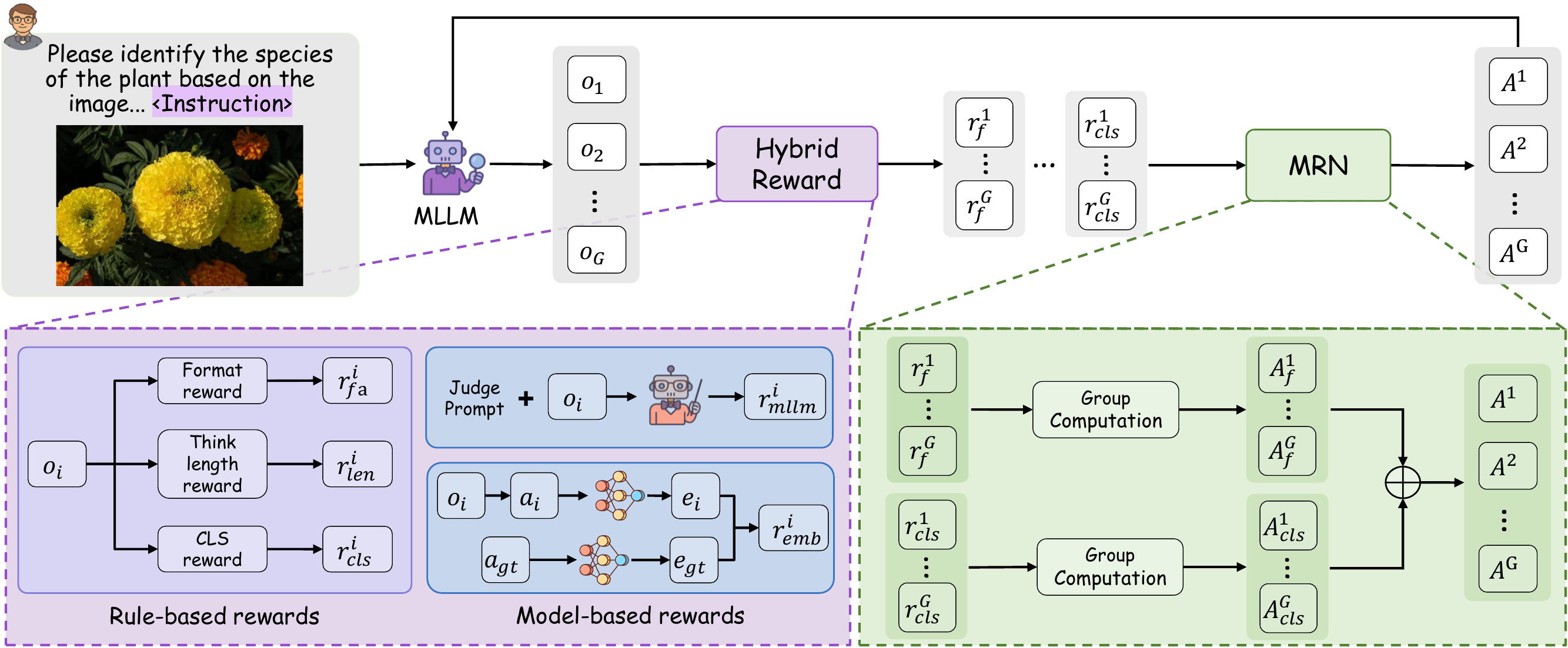
Motivation: The Cost of Thinking
CoT prompting consistently leads to accuracy degradation across all FGVC datasets. Non-reasoning models exhibit an average drop of 3–6% when switching from Answer-only to CoT prompts. More strikingly, during RFT, models exhibit Reasoning Collapse — they gradually suppress verbose reasoning while optimizing for accuracy.
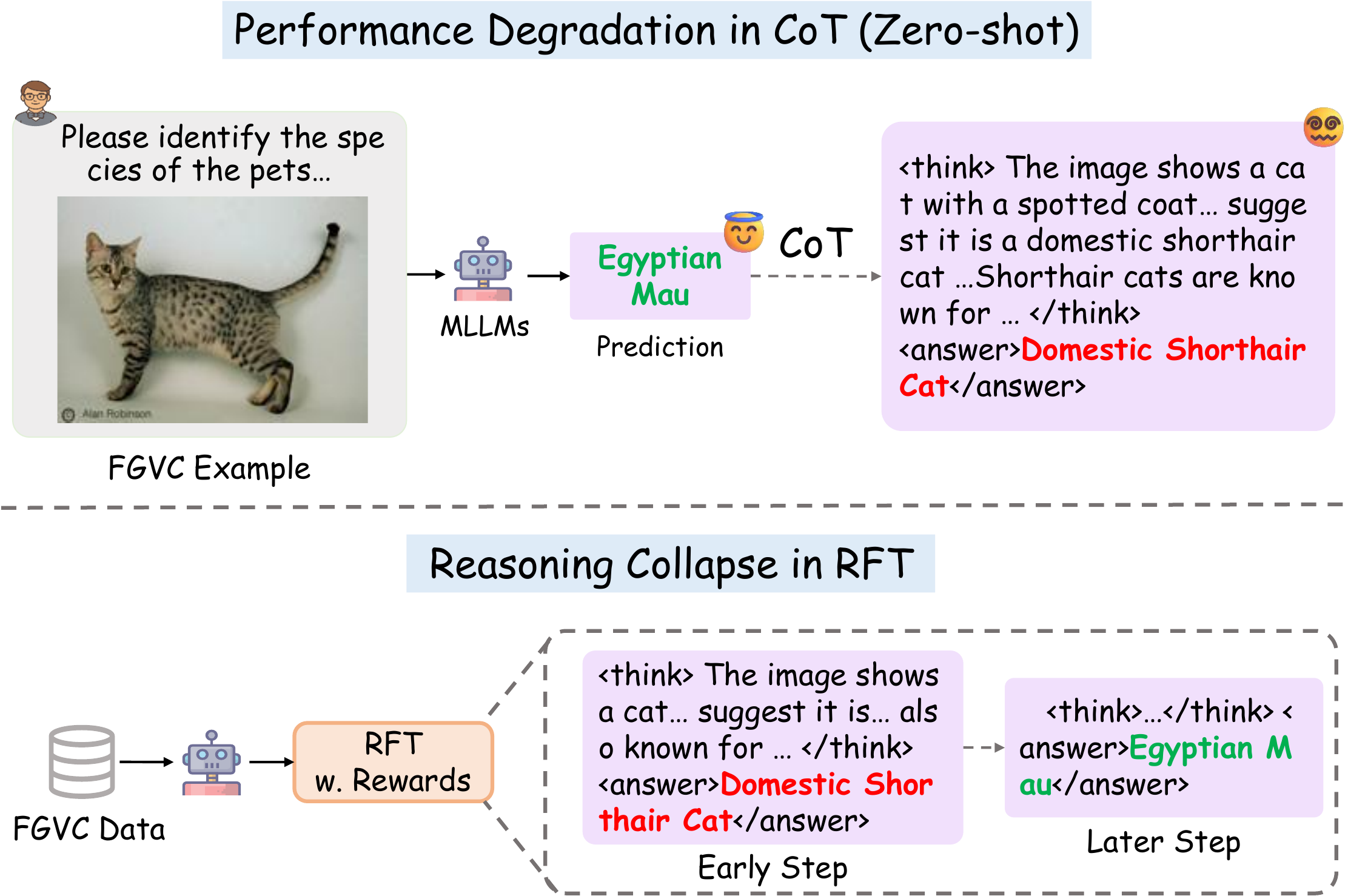
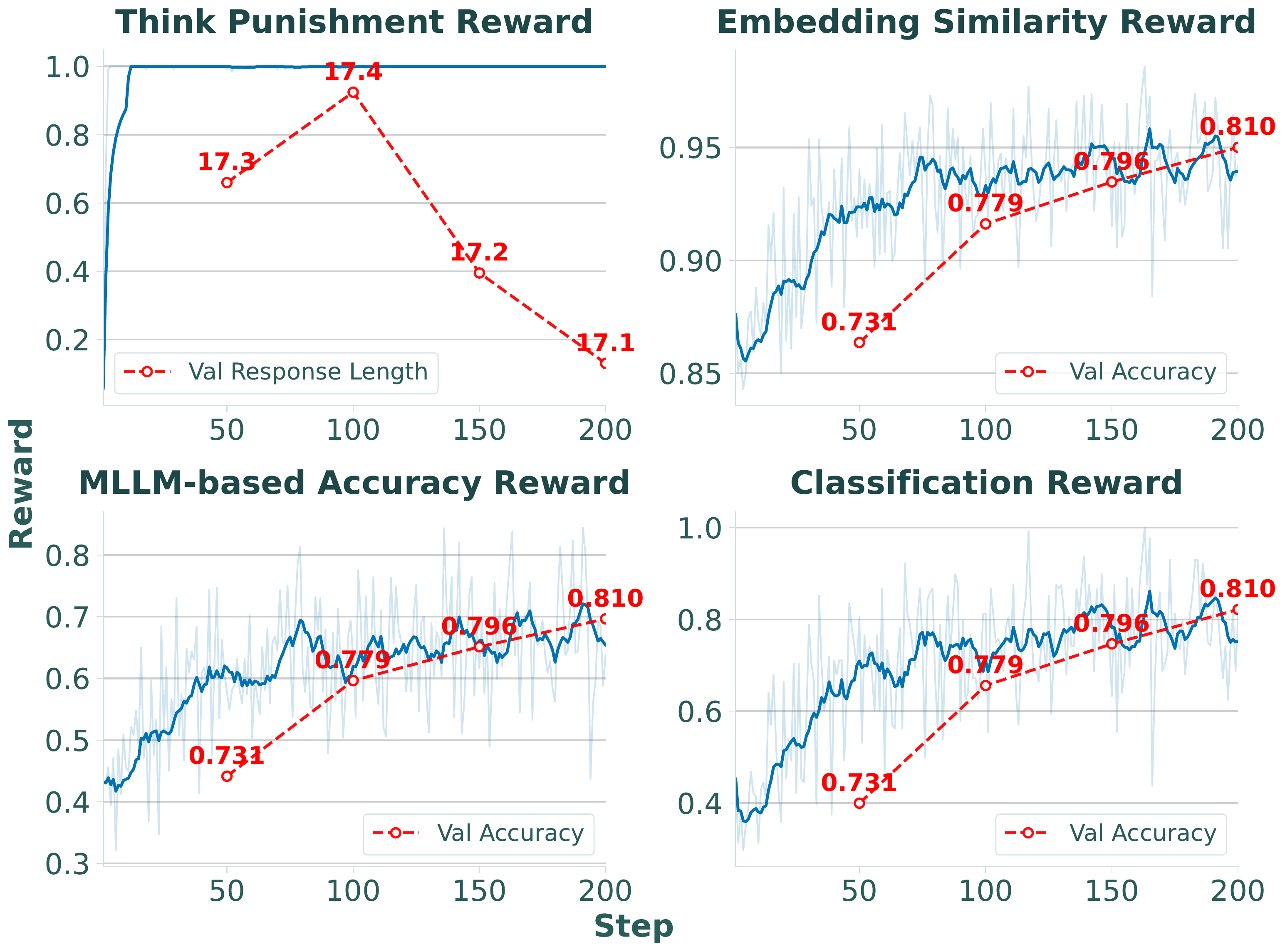
Fig 1
Performance degradation with CoT and Reasoning Collapse.
Zero-shot CoT leads to wrong answers despite correct direct prediction (top).
During RFT, reasoning length steadily shrinks while accuracy improves — an emergent Reasoning Collapse (bottom).
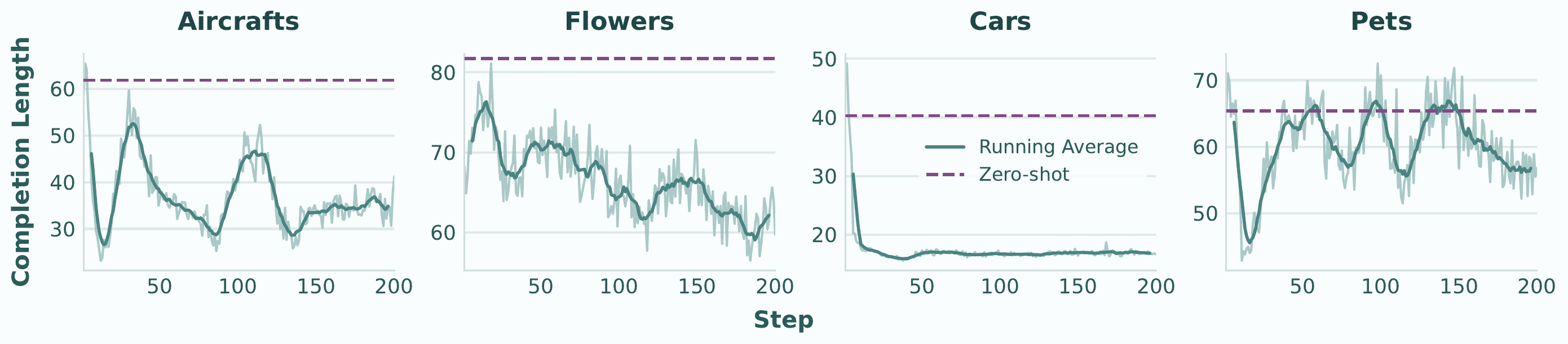
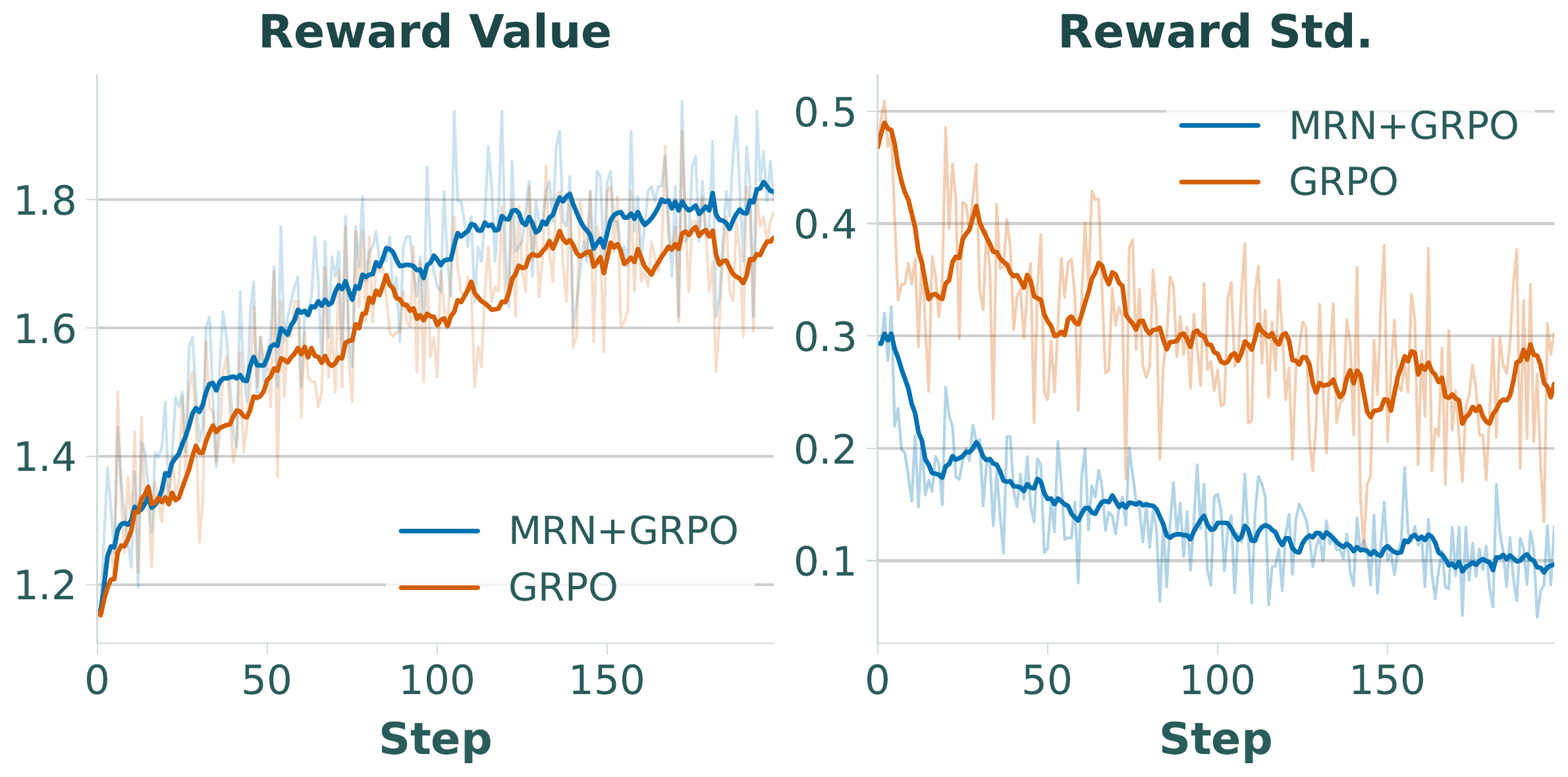
Fig 2
Reasoning length dynamics during RFT.
Completion length rapidly decreases and stabilizes at a compact range across all four FGVC datasets, suggesting RFT implicitly discourages excessive reasoning.
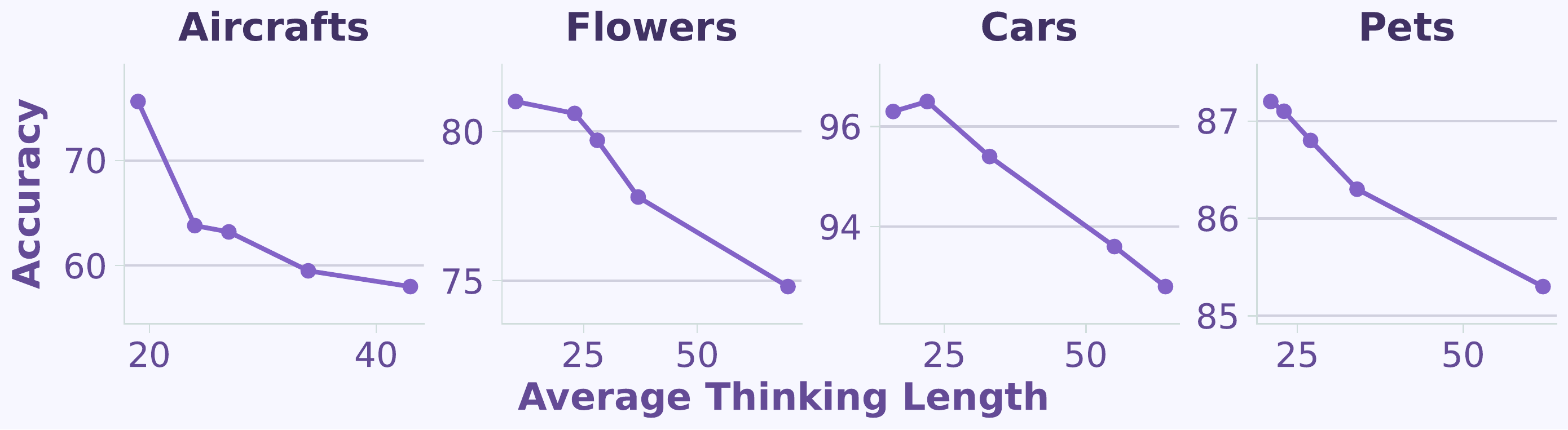
Fig 3
Reasoning length vs. accuracy.
As average thinking length increases, classification accuracy consistently declines across all FGVC benchmarks — a clear negative correlation.
🔍 Finding 1
For fine-grained visual tasks, thinking length is the key factor: excessive reasoning hurts performance, and MLLMs benefit more from concise responses than from elaborate reasoning.